I’d like to test the VarText newline character removal option on a csv import. How do we activate or select this option? RC4, Windows.
Select the Text > Shape Properties > Ignore Empty Vars
The 2 on the outside have the setting enabled
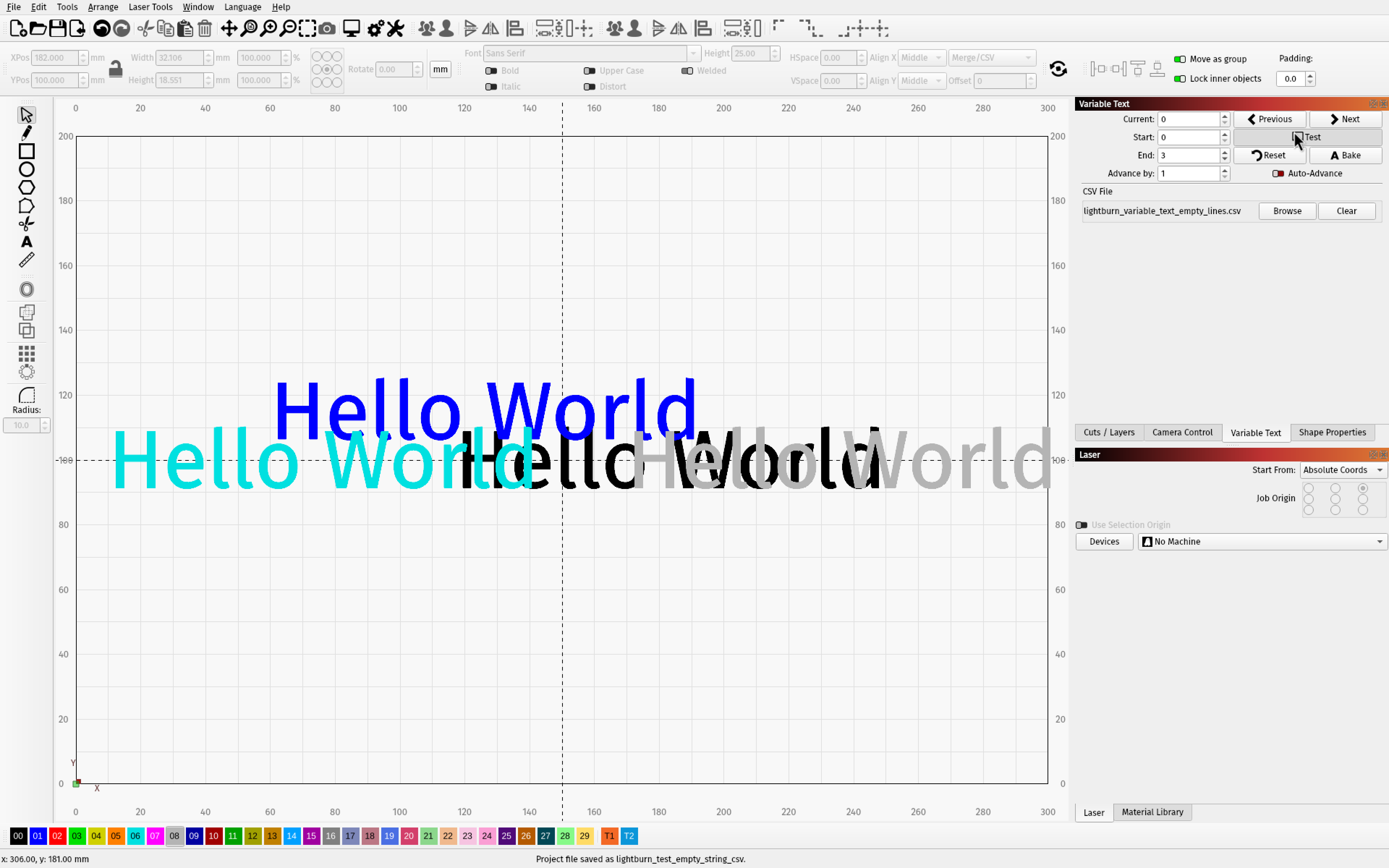
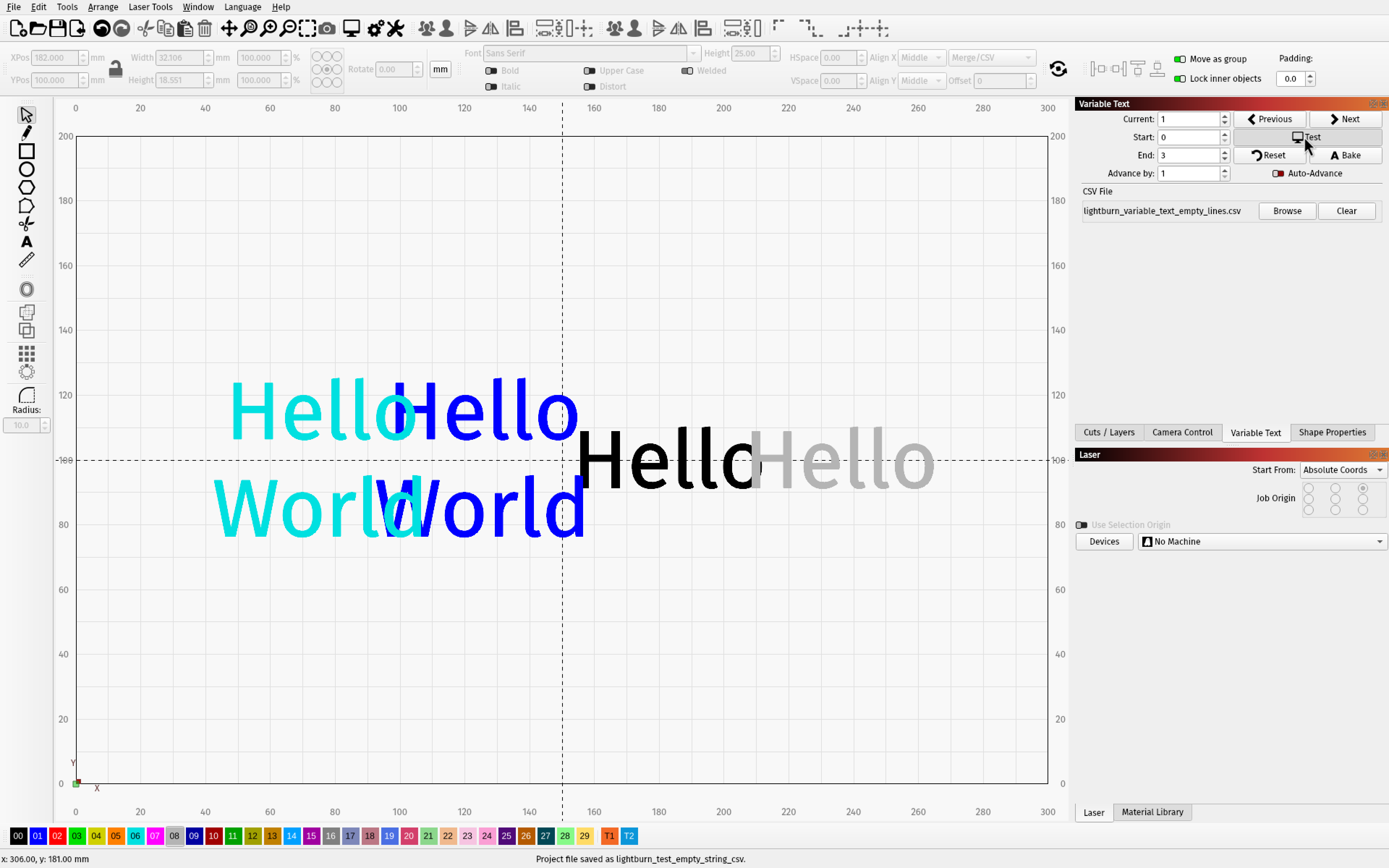
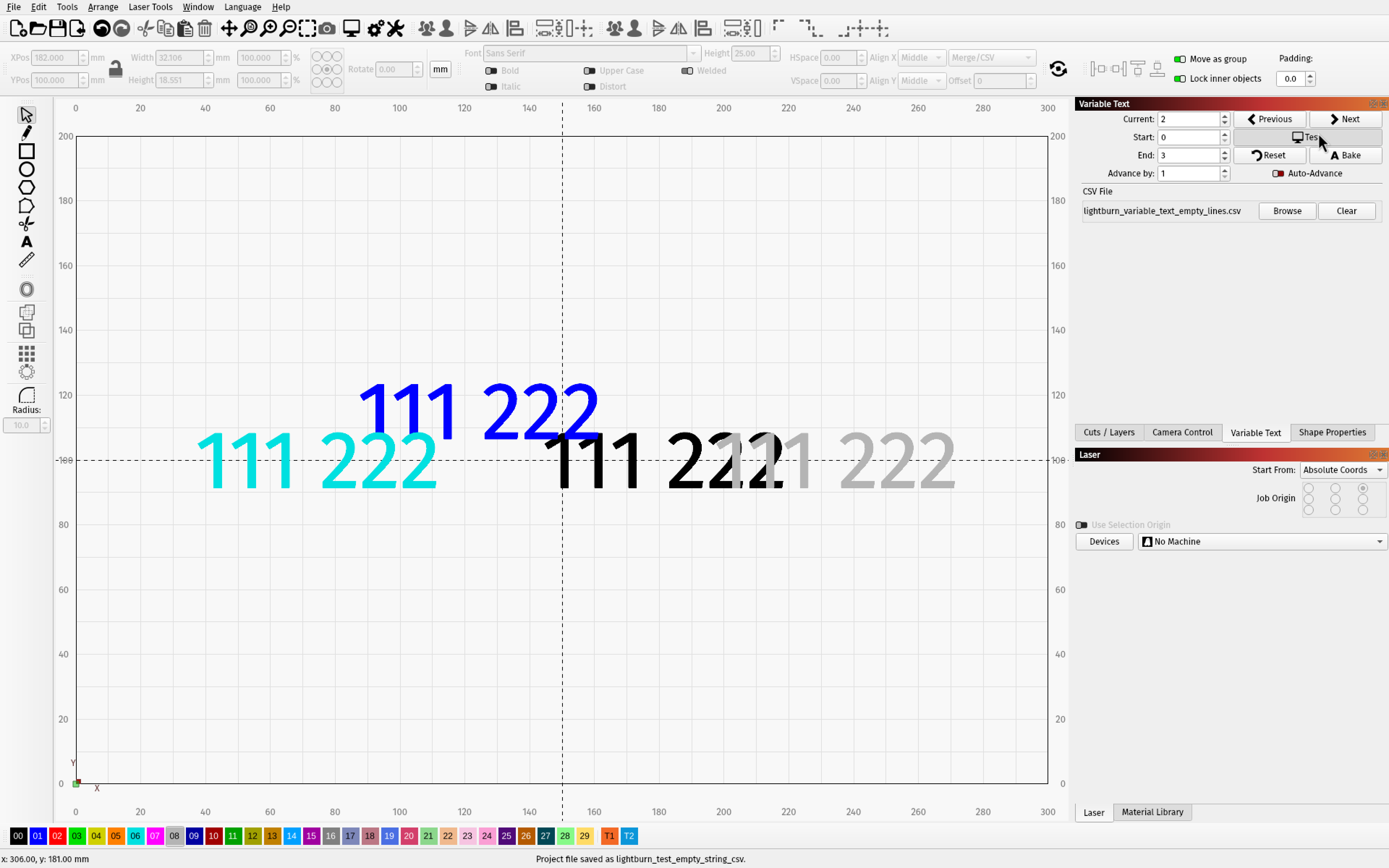
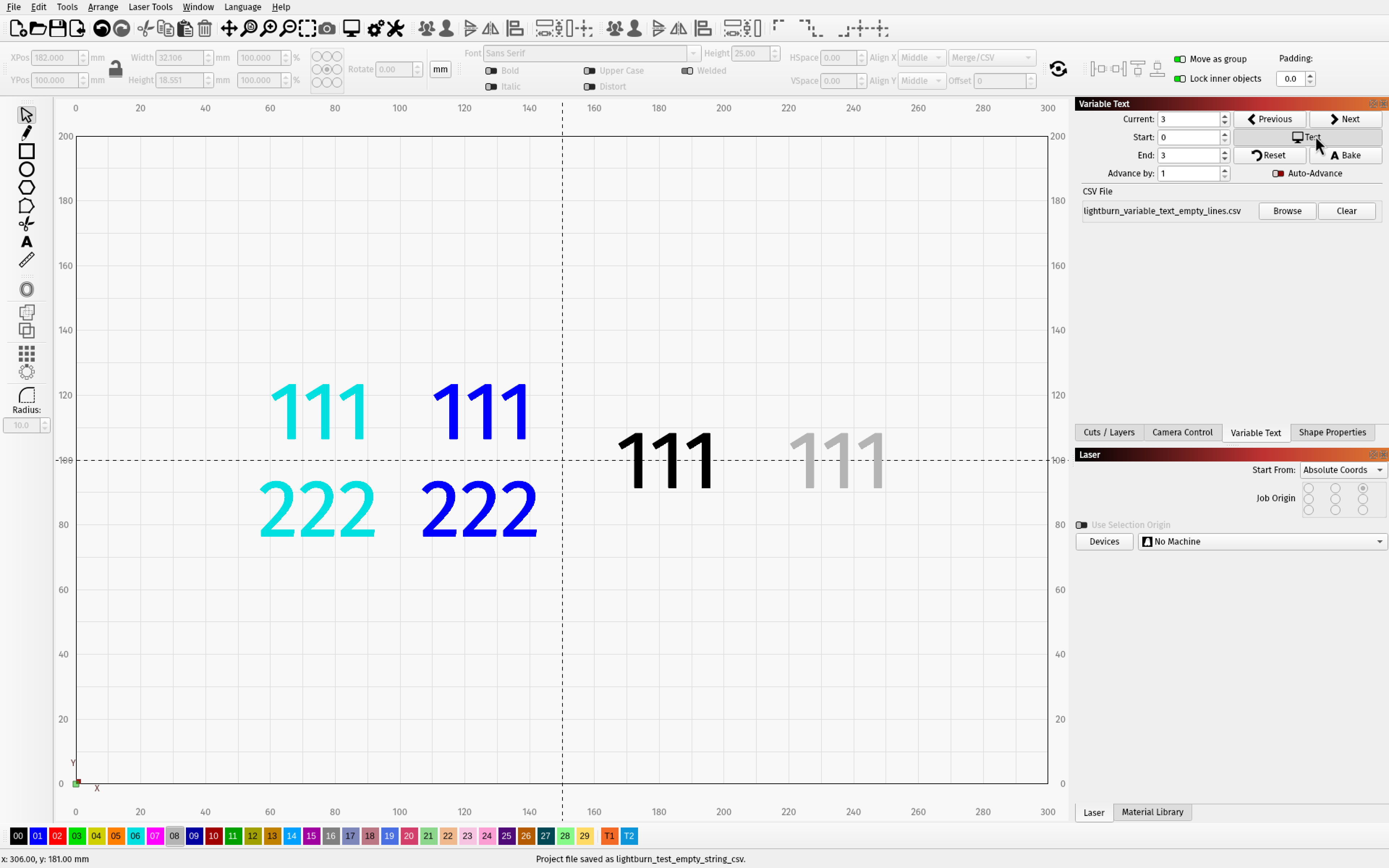
lightburn_test_empty_string_csv.lbrn2 (44.4 KB)
lightburn_variable_text_empty_lines.csv (42 Bytes)
1 Like
Thanks for sharing. Not sure how I missed that. This feature will be great.
It doesn’t seem to apply to the first (or multiple) leading blank fields. Note the last two cases in the example below have both kept a preceding newline.
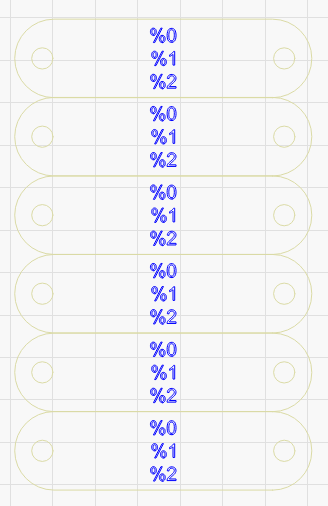
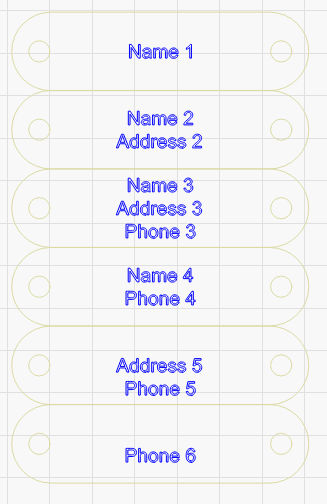
Variables1.csv (103 Bytes)
VariableTextTest.lbrn2 (86.9 KB)
FYI, @BetaMax @lightningstrike I split this off into its own topic so it didn’t flood the main thread.
1 Like
I’ve read somewhere only the first case is supported.
It’s a known tradeoff
@lightburn wrote
LightBurnSoftware · 2 days ago
This gets ugly. For example, if your format string is this:
%0 \n
%1
If omit the first column, you'd want the newline (\n) that follows it removed.
If you omitted the second column, you'd want the newline preceding it to be removed.
I'm going to make the code only work on preceding newlines, as I think that covers the most likely cases, but inevitably someone will come up with a reason this doesn't work for them.
1 Like
It’s never going to able to handle every possible case because I can’t know which newline characters you intended to be there and which ones you didn’t.
As long as you make sure that the columns in your CSV are “packed”, meaning only the endings are blank, with no in-between gaps, it should work as advertised.
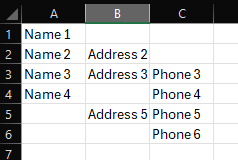
The way the parsing works with your file, starting at the “Address5” line:
%0 is evaluated, it finds a blank. There is no preceding \n (newline). There is a following newline, so that gets added to the output.
%1 is evaluated, it is not blank, so “Address5” gets added to the output, as does the newline that follows the %1 entry.
%2 is evaluated, it is not blank, so “Phone5” gets added to the output.
The problem is that when the first entry is blank, you’d want the newline that follows it to be removed, but for the last entry, you’d want the preceding newline removed. I have to pick one.
1 Like
This behaviour makes sense. Are the newline characters being filtered out after the text is merged into a complete string or one-by-one in process? If it’s a full string I can see how “%0 /n %1” effectively becomes “/n%1” if the the first field is blank, and that makes it preceding (in a sense) and a bit of a problem.
As far as the original template design from the user goes before merging (or most text editors) the /n is always a trailing character - end of line. Whether it’s at the end of a blank line, or following a variable field, it’s always trailing (or not present for the last line). If the fields are being merged one-by-one, can the trailing /n be removed if the importing field is blank? Then if the user wants to keep a particular new line, they can simply add a space into the csv field so it doesn’t get removed.
Newlines are removed one by one. As the source string is processed, the CSV content is looked up and inserted. If the CSV entry is blank and there is a preceding newline (and the flag is set), it’s removed.
Whether it’s trailing or preceding, there will always be a case where it’s ambiguous.
As I wrote in the response on Fider above:
This gets ugly. For example, if your format string is this:
%0 \n
%1
If omit the first column, you’d want the newline (\n) that follows it removed.
If you omitted the second column, you’d want the newline preceding it to be removed.
The newlines I have to be concerned with are the ones in your format string, not the ones in your CSV file.
Any chance of applying a Trim to the complete post merged string to clean up that one leading/trailing newline? Or as an option?
Sorry, not trying to drag on about this. I just have multiple customers I’m trying to support with this scenario for csv’s exported from shopify/woocommerce for orders with optional personalisation fields.
Why not create a macro in Excel to make a one click option to get it the way you want, you could even use notepad and do find and replace to get your desired result.
Yes, I could certainly do this, but i don’t expect all users have a programming background to solve this with workarounds the way you or I might.
My questions are intended as feedback for improvement in the release candidate. Should a user need to write custom macros or file parsers to work around this, and is it reasonable to expect it?
As a new option feature, I’d like to see this be the best it can be. There’s so much more power for simple batch automation with good features like these.
I only made one very simple test csv to hit this hurdle. I genuinely think this one known condition should be correctable by a user directly from the UI without having to potentially rework the csv.
1 Like
Fair point.
I’ve modified the code so it tries to remove the preceding newline, but if there isn’t one it checks to see the immediately following character is a newline, and if so, skips that instead.
Your file now does this:
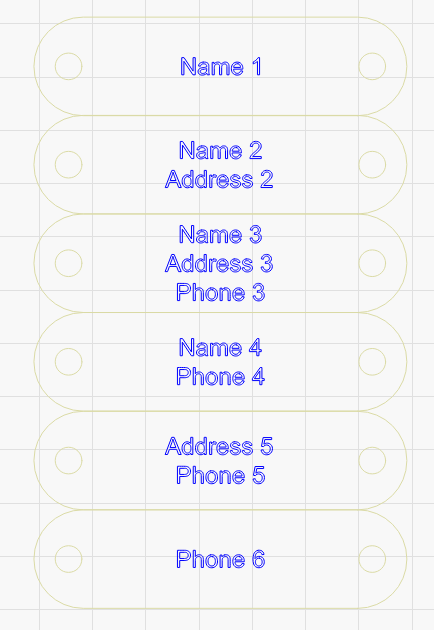
4 Likes
Thank you for this. Very much appreciated.
1 Like
This topic was automatically closed 30 days after the last reply. New replies are no longer allowed.