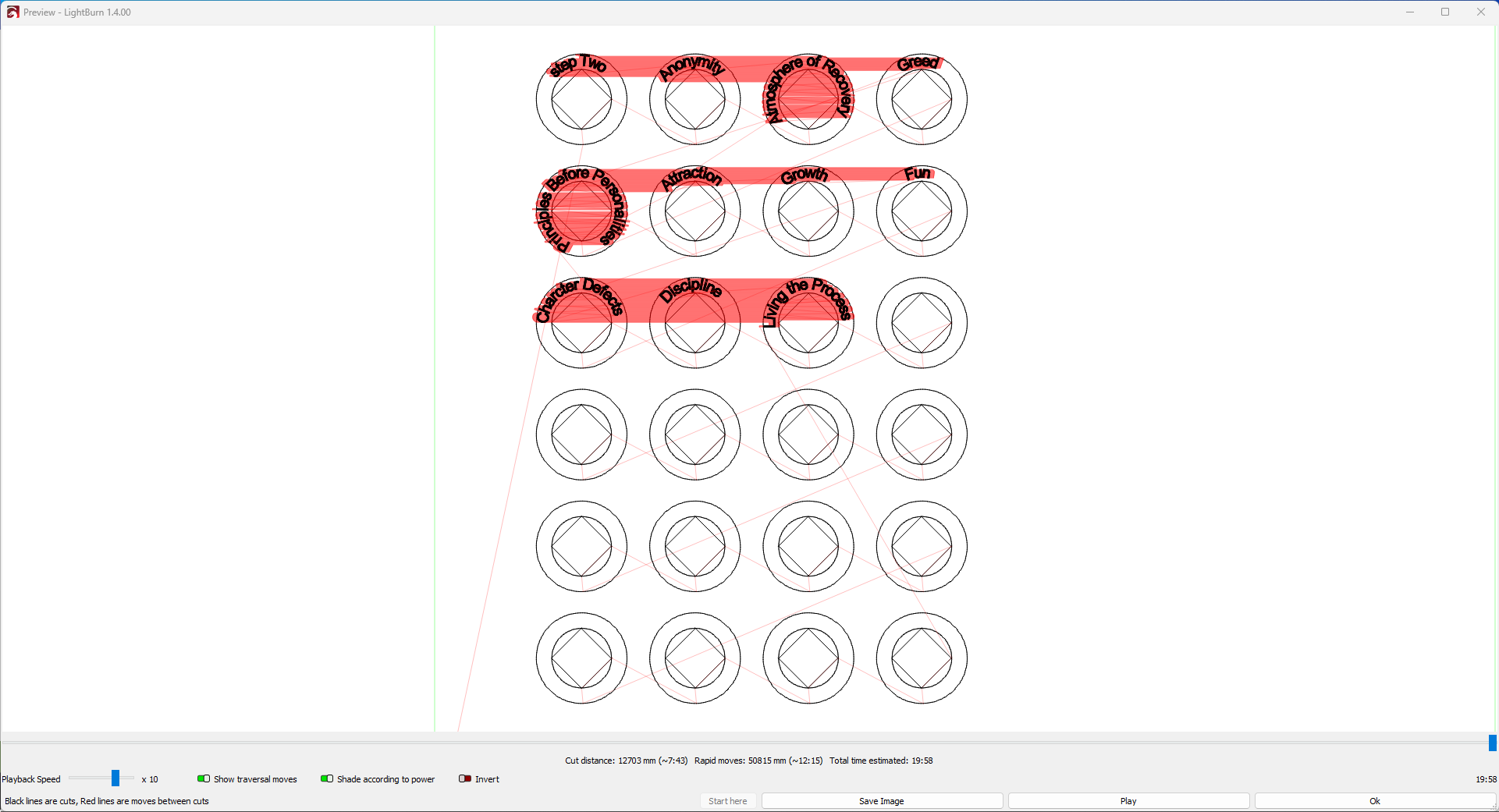
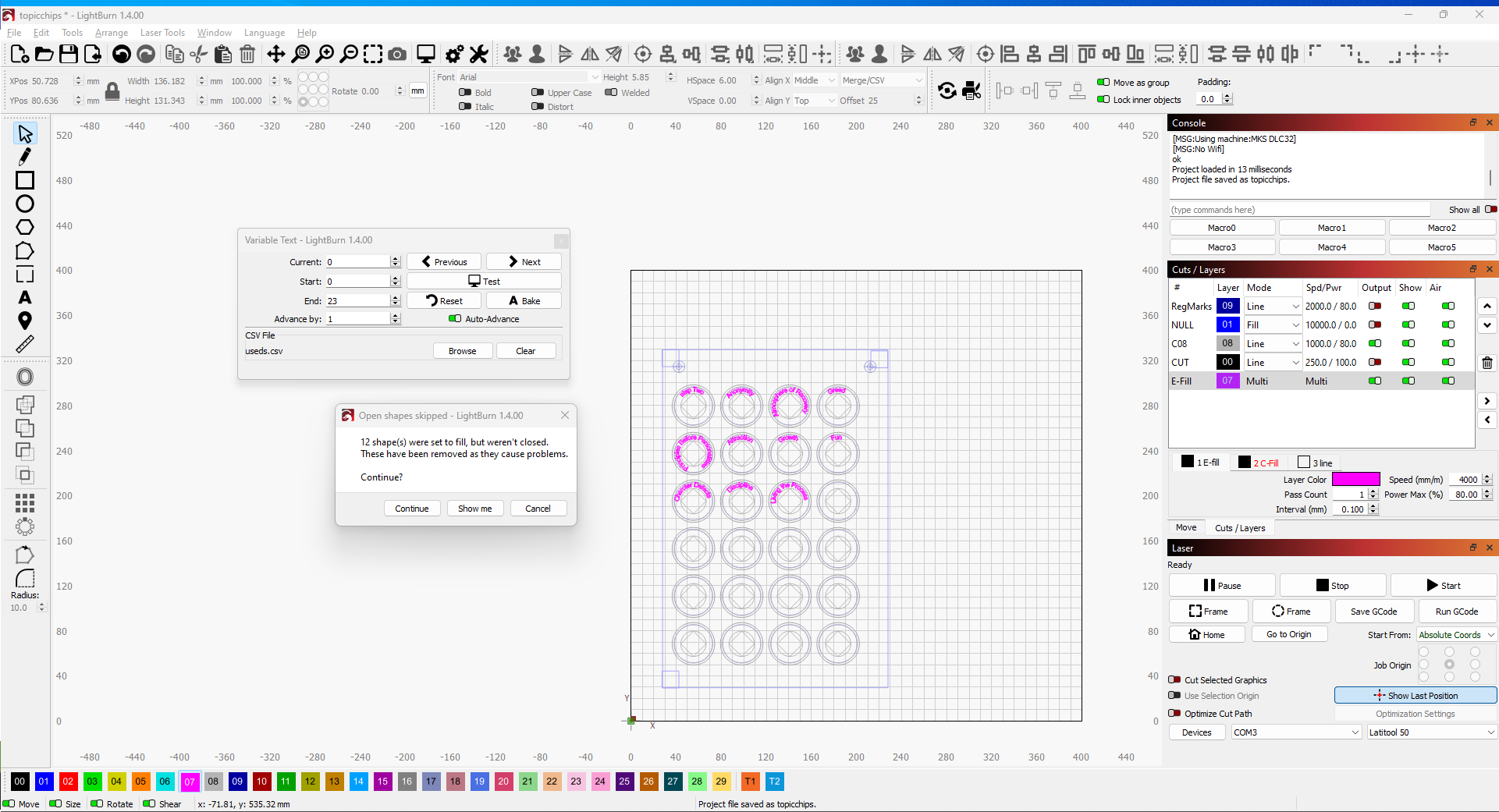
I am trying to make 24 chips each with a different word on them. I created some text with simply %0 as the content and slected merge/csv as text type. I created the 24 chips using the array function. I loaded a text file with a single text entry on a row in the variable text manager. (see image below. When I preview only some of the text fields are populated. Wtih the first word being on anywhere from the fifth to the tenth row. I am uploading several screenshots and the cvs file. If anybody can give me a clue how to fix thi I would greatly appreciate this.
I gimmicked up a test layout with text in six rows of four columns.
Stripping all the commas out didn’t change the results, so the import function assumes whatever’s on the line must be the first field, with no need for a trailing comma field delimiter.
Having 19 lines in the CSV file and 24 chips in the layout produces the “unclosed shapes” error message: the CSV import sends empty text to the text generation function, which then falls on its face. Matching those two counts may require adding lines with dummy (not blank!) text to the CSV file or, perhaps, duplicating a few lines to get a few spare chips.
Some earlier discussions:
Also: “Finanaces” seems misspelled. I hate it when that happens when I’ve done so much proofreading and show it to somebody else, who instantly sees what I didn’t.